1.HELM
https://github.com/helm/helm/blob/master/docs/charts.md
什么是 Helm
在没使用 helm 之前,向 kubernetes 部署应用,我们要依次部署 deployment、svc 等,步骤较繁琐。况且随着很多项目微服务化,复杂的应用在容器中部署以及管理显得较为复杂,helm 通过打包的方式,支持发布的版本管理和控制,很大程度上简化了 Kubernetes 应用的部署和管理
Helm 本质就是让 K8s 的应用管理(Deployment,Service 等 ) 可配置,能动态生成。通过动态生成 K8s 资源清单文件(deployment.yaml,service.yaml)。然后调用 Kubectl 自动执行 K8s 资源部署
Helm 是官方提供的类似于 YUM 的包管理器,是部署环境的流程封装。Helm 有两个重要的概念:chart 和 release
- chart 是创建一个应用的信息集合,包括各种 Kubernetes 对象的配置模板、参数定义、依赖关系、文档说明等。chart 是应用部署的自包含逻辑单元。可以将 chart 想象成 apt、yum 中的软件安装包
- release 是 chart 的运行实例,代表了一个正在运行的应用。当 chart 被安装到 Kubernetes 集群,就生成一个 release。chart 能够多次安装到同一个集群,每次安装都是一个 release
Helm 包含两个组件:Helm 客户端和 Tiller 服务器,如下图所示
[
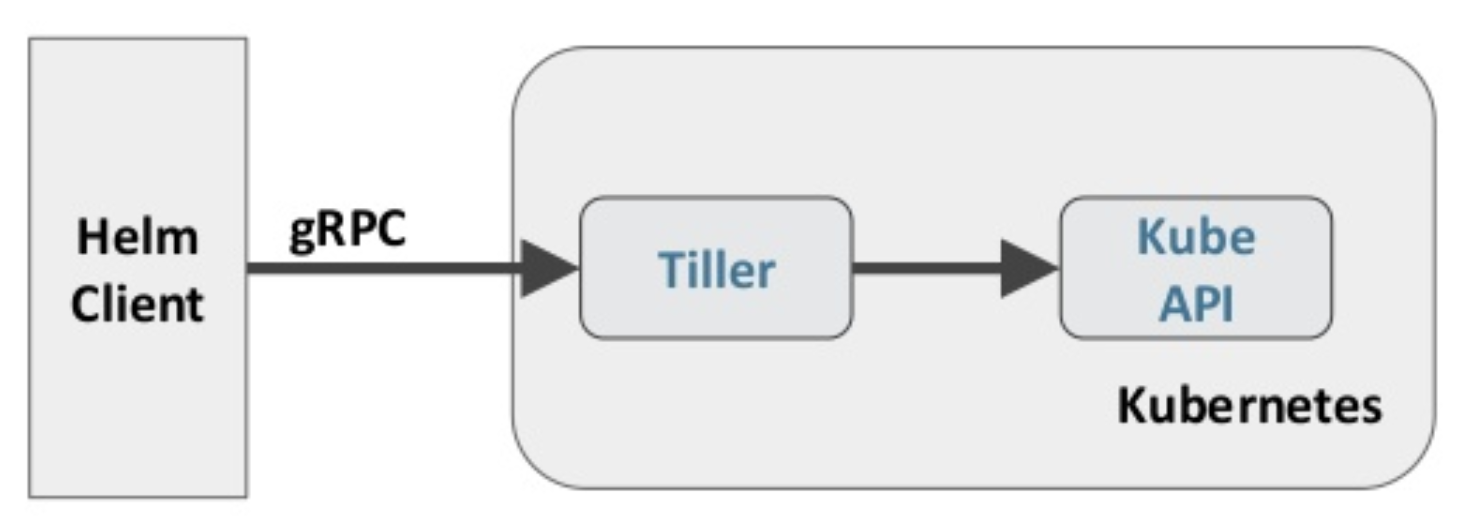
Helm 客户端负责 chart 和 release 的创建和管理以及和 Tiller 的交互。Tiller 服务器运行在 Kubernetes 集群中,它会处理 Helm 客户端的请求,与 Kubernetes API Server 交互
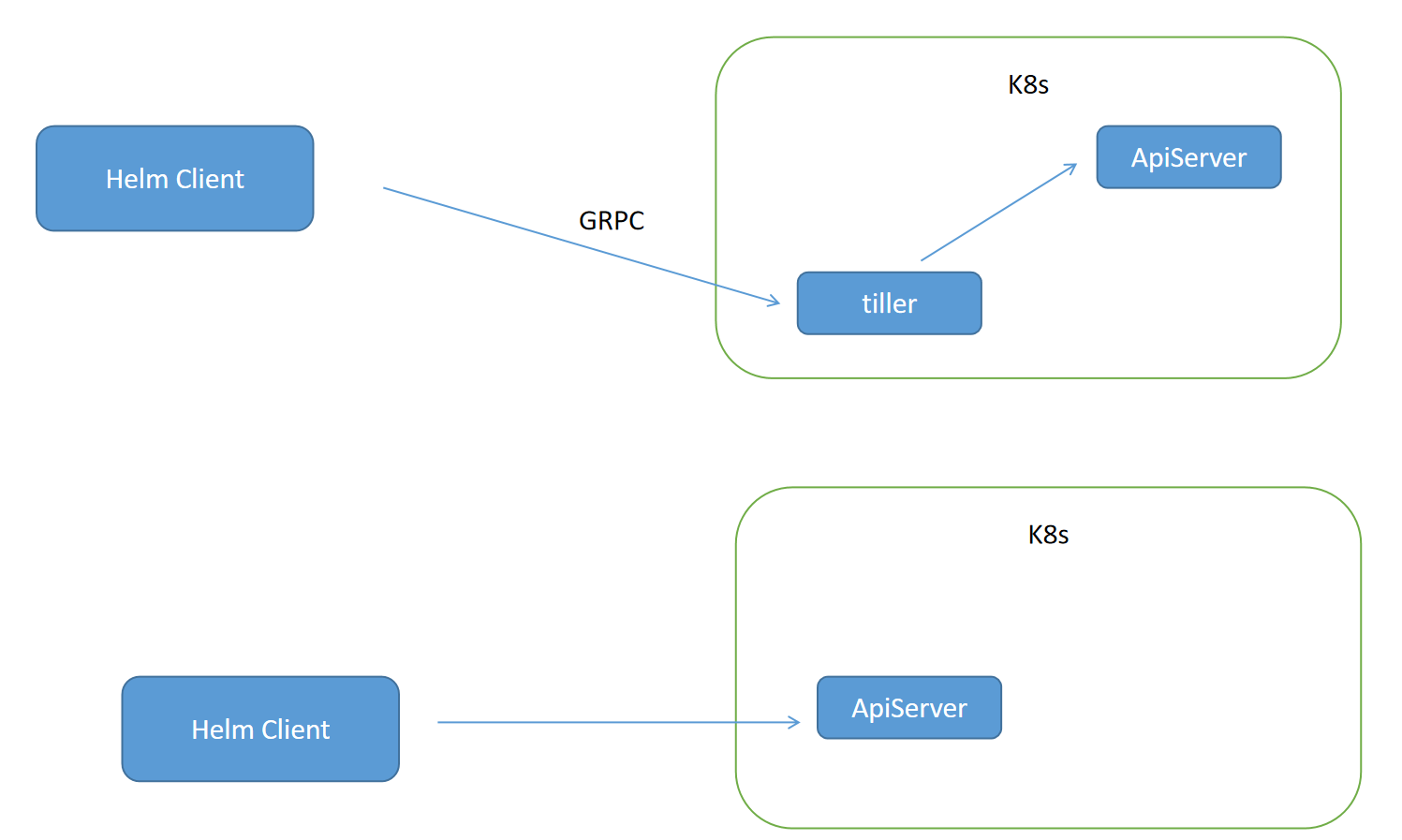
HELM版本区别:V2和v3
- v2会通过GRPC连接tiller组件,grpc是谷歌开发的一种以二进制文件作为传输对象的运城过程调用,主要用在客户端开发;helm把资源清单发给tiller,tiller也是一个容器,因为在以前的版本中RBAC没有成为主流,还有一些ABAC,而ABAC必须要有一个绑定的实体才能承载权限,不能直接绑定helm(helm用的时候在,不用的时候不在),而tiller嗲用apiserver去执行资源清单
- 目前正在演替,太多太多的公司写了太多太多的chart在v2版中,所以目前正在交替,未来应该还是会以3为主,但是helm在v2版也是支持RBAC的

Helm 部署
越来越多的公司和团队开始使用 Helm 这个 Kubernetes 的包管理器,我们也将使用 Helm 安装 Kubernetes 的常用组件。 Helm 由客户端命 helm 令行工具和服务端 tiller 组成,Helm 的安装十分简单。 下载 helm 命令行工具到 master 节点 node1 的 /usr/local/bin 下,这里下载的 2.13. 1版本:
# grpc会拿时间戳确认数据是否安全一致,所以需要同步
$ ntpdate ntp1.aliyun.com
$ wget https://storage.googleapis.com/kubernetes-helm/helm-v2.13.1-linux-amd64.tar.gz
$ tar -zxvf helm-v2.13.1-linux-amd64.tar.gz
$ cd linux-amd64/
$ cp helm /usr/local/bin/
#helm也可以不在master端,它也是用过kubeconfig找到tiller组件的为了安装服务端 tiller,还需要在这台机器上配置好 kubectl 工具和 kubeconfig 文件,确保 kubectl 工具可以在这台机器上访问 apiserver 且正常使用。 这里的 node1 节点以及配置好了 kubectl
因为 Kubernetes APIServer 开启了 RBAC 访问控制,所以需要创建 tiller 使用的 service account: tiller 并分配合适的角色给它。 详细内容可以查看helm文档中的 Role-based Access Control。 这里简单起见直接分配 cluster- admin 这个集群内置的 ClusterRole 给它。创建 rbac-config.yaml 文件:
apiVersion: v1
kind: ServiceAccount
metadata:
name: tiller
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: tiller
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: tiller
namespace: kube-system$ kubectl create -f rbac-config.yaml
serviceaccount/tiller created
clusterrolebinding.rbac.authorization.k8s.io/tiller created# 初始化helm,指定sa名字是tiller,跳过刷新,这个刷新就是向官方库同步数据(在国外)
$ helm init --service-account tiller --skip-refreshtiller 默认被部署在 k8s 集群中的 kube-system 这个namespace 下
$ kubectl get pod -n kube-system -l app=helm
NAME READY STATUS RESTARTS AGE
tiller-deploy-c4fd4cd68-dwkhv 1/1 Running 0 83s$ helm version
Client: &version.Version{SemVer:"v2.13.1", GitCommit:"618447cbf203d147601b4b9bd7f8c37a5d39fbb4", GitTreeState:"clean"}
Server: &version.Version{SemVer:"v2.13.1", GitCommit:"618447cbf203d147601b4b9bd7f8c37a5d39fbb4", GitTreeState:"clean"}Helm 自定义模板
# 创建文件夹
$ mkdir ./hello-world
$ cd ./hello-world# 创建自描述文件 Chart.yaml , 这个文件必须有 name 和 version 定义
$ cat <<'EOF' > ./Chart.yaml
name: hello-world
version: 1.0.0
email: lztccc0831@163.com
EOF# 创建模板文件, 用于生成 Kubernetes 资源清单(manifests)
$ mkdir ./templates
$ cat <<'EOF' > ./templates/deployment.yaml
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: hello-world
spec:
replicas: 1
template:
metadata:
labels:
app: hello-world
spec:
containers:
- name: hello-world
image: xxxxxxx/myapp:v1
ports:
- containerPort: 80
protocol: TCP
EOF
$ cat <<'EOF' > ./templates/service.yaml
apiVersion: v1
kind: Service
metadata:
name: hello-world
spec:
type: NodePort
ports:
- port: 80
targetPort: 80
protocol: TCP
selector:
app: hello-world
EOF# 使用命令 helm install RELATIVE_PATH_TO_CHART 创建一次Release
$ helm install .
# . 代表从当前目录开始创建release
# 或者去helm.sh添加仓库地址,然后网络下载注意,在install的时候这个目录中不要有和安装以外其他相关的东西,不然会超过grpc的传输大小限制
常用命令
# 列出已经部署的 Release
$ helm ls
# 查询一个特定的 Release 的状态
$ helm status RELEASE_NAME
# 移除所有与这个 Release 相关的 Kubernetes 资源
$ helm delete cautious-shrimp
# helm rollback RELEASE_NAME REVISION_NUMBER
$ helm rollback cautious-shrimp 1
# 使用 helm delete --purge RELEASE_NAME 移除所有与指定 Release 相关的 Kubernetes 资源和所有这个 Release 的记录
$ helm delete --purge cautious-shrimp
$ helm ls --deleted动态生成
# 配置体现在配置文件 values.yaml
$ cat <<'EOF' > ./values.yaml
image:
repository: wangyanglinux/myapp
tag: v1
EOF
# 这个文件中定义的值,在模板文件中可以通过 .VAlues对象访问到
$ cat <<'EOF' > ./templates/deployment.yaml
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: hello-world
spec:
replicas: 1
template:
metadata:
labels:
app: hello-world
spec:
containers:
- name: hello-world
image: {{ .Values.image.repository }}:{{ .Values.image.tag }}
ports:
- containerPort: 80
protocol: TCP
EOF
# 在 values.yaml 中的值可以被部署 release 时用到的参数 --values YAML_FILE_PATH 或 --set key1=value1, key2=value2 覆盖掉
$ helm install --set image.tag='latest' .
# 升级版本
helm upgrade -f values.yaml test .Debug
很重要,直接生成资源清单,很方便
# 使用模板动态生成K8s资源清单,非常需要能提前预览生成的结果。
# 使用--dry-run --debug 选项来打印出生成的清单文件内容,而不执行部署
helm install . --dry-run --debug --set image.tag=latestfetch
helm fetch 库名/包名下载离线的压缩包,在官方网络不回应的时候
还可以--version 版本号
这样就可以下载下来放在U盘里,需要使用的时候直接把目录拿过去 helm install . 就好了
如果原有的chart包中的yaml文件太多,需要改的地方不好找
我们可以创建一个新的yaml文件,把需要修改的资源写在这里
他会自动把新的作为执行对象,老的当做默认版本去执行
2.EFK
-
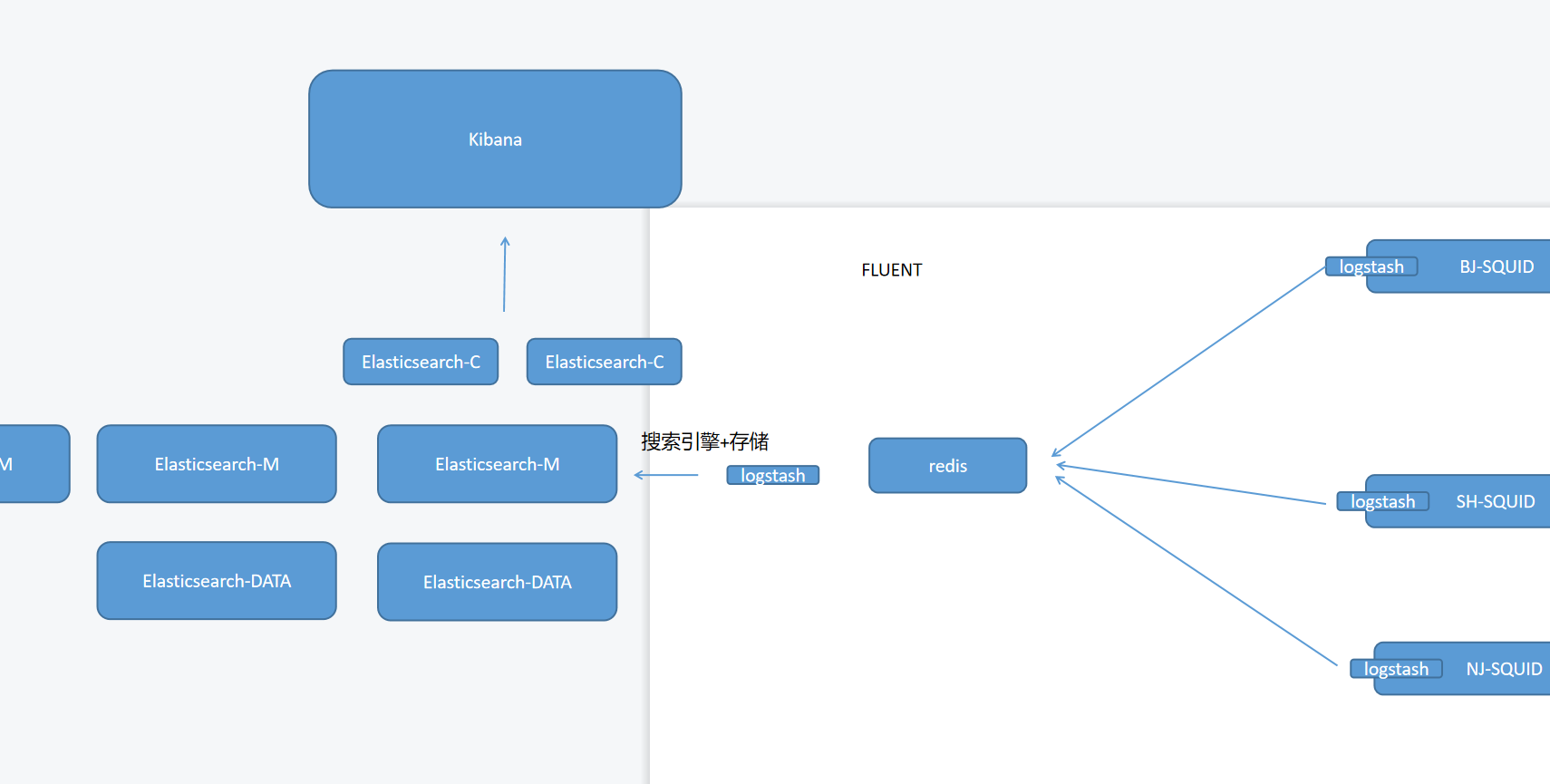
logstash会以守护进程的方式运行在各个节点,它允许我们指定一个目录,在规定时间内,以数据流的方式把目录中的文件发送出去而且是发送新的数据,而不是所有的都发送。他还支持过滤,一些关键字可以过滤掉,还支持替换关键字
-
可能很多的数据流一起发给Elasticsearch,他也可能撑不住,就可以加个Redis,让Redis当缓存,一点点的去读,还能汇总再过滤
-
Elasticsearch:搜索引擎+存储,就像百度的时候,搜索两个字就会提示后面可能想找的内容,实际上是切片存储,Elasticsearch也是这样,切片会得到很多索引,别人只需要搜素关键字就能找到
-
Elasticsearch的master需要投票机制,投出谁是真的主,真正的master才能对数据切片,所以三个节点。client端是以http协议向外暴露API接口,这样其他的语言就能对应到Elasticsearch进行查询了,两个节点就够。data是镜像的形式,两个节点也够
-
kibana:由于elasticsearch有自己的语言,没必要为了查日志学一门语言,kibana就是专门对接到elasticsearch进行查询的
-
目前ELK已经被阿里收购了,算是国产软件,但是这一套组件都是通过Java语言写的,性能足够,但是资源占用太多,只是为了收集数据花费几十个G没必要。所以有了Fluentd,是通过R语言写的,解决了内存指针的问题,被誉为安全时代的C语言,资源占用很低,替代了logstash,也就是EFK
-
其实EFK用在k8s集群中有点大材小用,因为她更适合在公网环境中进行日志收集
添加 Google incubator 仓库
helm repo add incubator http://storage.googleapis.com/kubernetes-charts-incubator部署 Elasticsearch
kubectl create namespace efk
helm fetch incubator/elasticsearch
helm install --name els1 --namespace=efk -f values.yaml incubator/elasticsearch
kubectl run cirror-$RANDOM --rm -it --image=cirros -- /bin/sh
curl Elasticsearch:Port/_cat/nodes
# 这个可以看见Elasticsearch集群中所有的角色,正常应该有三个master,两个客户端,两个data
# 这条命令类似于docker run --name $RANDOM --rm -it cirros:latest /bin/sh
# cirros就是镜像非常小,但是有基本命令的测试镜像
注意,elasticsearch和kibana的子版本必须相同,如果不相同,不会报错,但就是连接不上
xpackEnable: false
这个插件可以监控当前EFK或者ELK的工作状态,但是这是个收费的功能
部署 Fluentd
Fluent会以daemonset的方式去每个节点收集日志,在/var/log/containers下收集,然后以数据流的方式发给elasticsearch
因为在daemon.json文件中写了
原理是在docker设置daemon.json,将他的日志存储驱动引擎指向json-file,他会把所有的容器的日志放在/var/log/containers下,然后fluentd会以hostpath的方式把这个目录挂载到fluentd的容器下,然后再把数据通过fluentd进程发送至elasticsearch
helm fetch stable/fluentd-elasticsearch
vim values.yaml
# 更改其中 Elasticsearch 访问地址
helm install --name flu1 --namespace=efk -f values.yaml stable/fluentd-elasticsearch部署 kibana
kibana可以和ingress中的basicauth结合,因为kibana本身没有目录保护,任何人都可以访问过去
helm fetch stable/kibana --version 0.14.8
helm install --name kib1 --namespace=efk -f values.yaml stable/kibana --version 0.14.83.Prometheus
Prometheus就不是通过agent端去收集信息的,而是通过网页。
就是说打开一个web接口,写一个web界面,在这个页面上写着kv结构,Prometheus会自动把这些数据抓走当做监控的数据
例如: CPU:2
mem:23实现代价非常的低
Prometheus
- 实际上就是个时序数据库,画图很弱,他有自己的PQL语句,很麻烦,所以Prometheus一般不单独使用
时序数据库:
- x轴是时间,y轴进行数据记录
altermanager
- 数据库没有报警功能,altermanager就相当于触发器,报警的功能
EXPOTER
- 将当前的监控数据获取以后展示出来,是一个抽象型的web服务器,收集到数据以后就把数据以kv格式,一行一个展示出来
Grafana
- 很老牌的软件了,主要负责图形展示,Grafana可以比zabbix更详细的展示图表,同时没有存储能力依附于别的数据库,也可以对接到zabbix上
由于Prometheus的部署需要多个组件之间互相配合,所以它的部署很麻烦
在Kubernetes中有内置控制器,同时用户可以以根据需求自定义控制器(CRD),可以对应应用在实际的环境中,比如mysql控制器,一创建就是一个mysql
而普罗米修斯同样有它的控制器,一创建就是一个Prometheus,也是CoreOS开发的
Operator 是何物
Kubernetes Operator 是一种封装、部署和管理 Kubernetes 应用的方法。我们使用 Kubernetes API(应用编程接口)和 kubectl 工具在 Kubernetes 上部署并管理 Kubernetes 应用
就是Kubernetes如果想自定义一个控制器或者安装一些组件,那么就需要事先把该准备的东西都准备好(框架),就是事先搭好的脚手架,也就是operator
相关地址信息
Prometheus github 地址:https://github.com/coreos/kube-prometheus
组件说明
1.MetricServer:是 kubernetes 集群资源使用情况的聚合器,收集数据给 kubernetes 集群内使用,如kubectl,hpa,scheduler等
2.PrometheusOperator:是一个系统监测和警报工具箱,用来存储监控数据
3.NodeExporter:用于各 node 的关键度量指标状态数据
4.KubeStateMetrics:收集k ubernetes 集群内资源对象数据,制定告警规则
5.Prometheus:采用pull方式收集 apiserver,scheduler,controller-manager,kubelet 组件数据,通过http 协议传输
6、Grafana:是可视化数据统计和监控平台
构建记录
$ git clone https://github.com/coreos/kube-prometheus.git
cd /root/kube-prometheus/manifests修改 grafana-service.yaml 文件,使用 nodepode 方式访问 grafana:
$ vim grafana-service.yaml
apiVersion: v1
kind: Service
metadata:
name: grafana
namespace: monitoring
spec:
type: NodePort #添加内容
ports:
- name: http
port: 3000
targetPort: http
nodePort: 30100 #添加内容
selector:
app: grafana修改 prometheus-service.yaml,改为 nodepode
$ vim prometheus-service.yaml
apiVersion: v1
kind: Service
metadata:
labels:
prometheus: k8s
name: prometheus-k8s
namespace: monitoring
spec:
type: NodePort
ports:
- name: web
port: 9090
targetPort: web
nodePort: 30200
selector:
app: prometheus
prometheus: k8s修改 alertmanager-service.yaml,改为 nodepode
vim alertmanager-service.yaml
apiVersion: v1
kind: Service
metadata:
labels:
alertmanager: main
name: alertmanager-main
namespace: monitoring
spec:
type: NodePort
ports:
- name: web
port: 9093
targetPort: web
nodePort: 30300
selector:
alertmanager: main
app: alertmanager4.HPA与资源限制
想要使用kubectl top命令,首先需要安装metrics,一般在监控中都会附带
Horizontal Pod Autoscaling
HPA 可以根据 CPU 利用率自动伸缩 RC、Deployment、RS 中的 Pod 数量
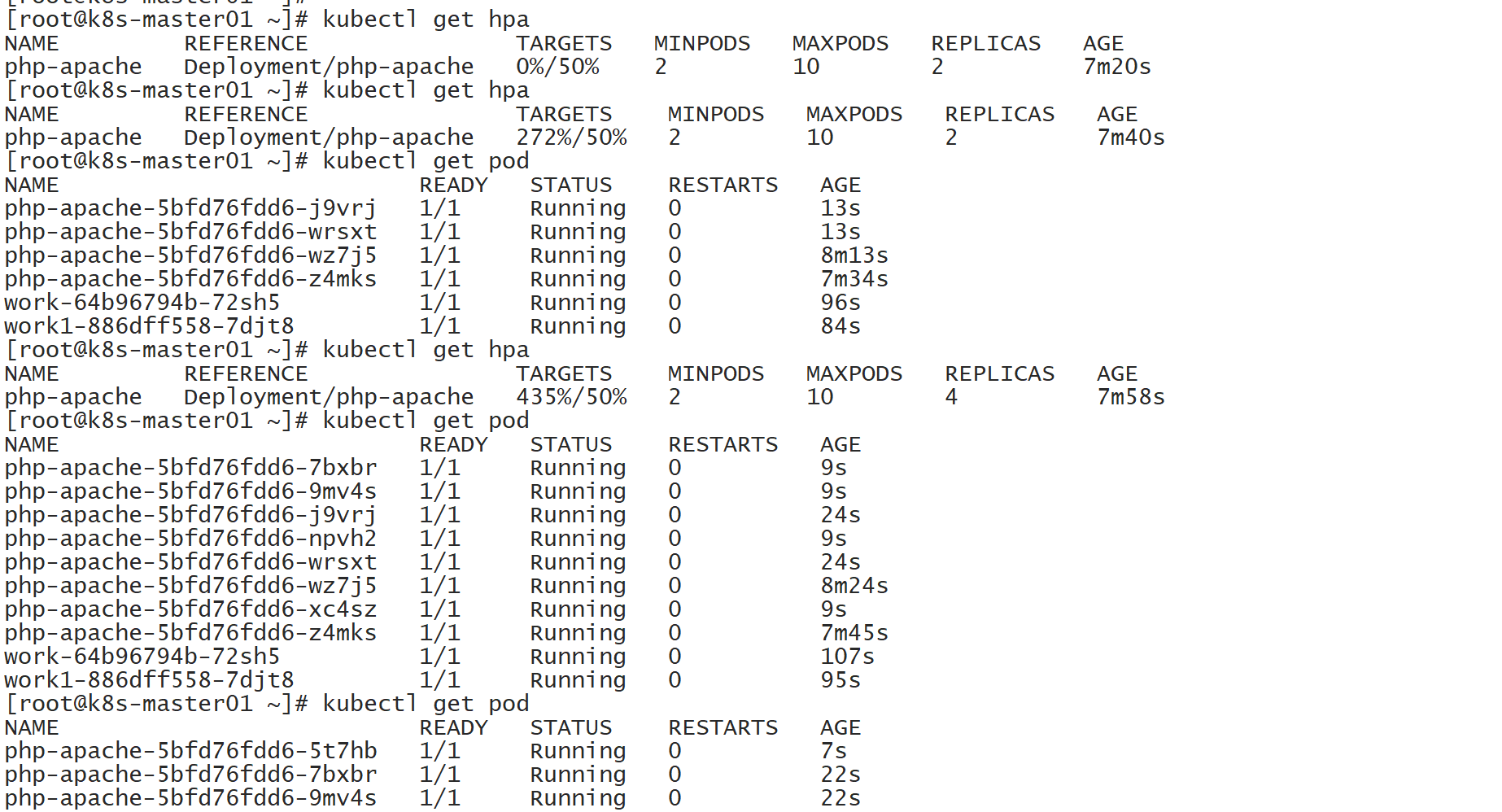
$ kubectl run php-apache --image=wangyanglinux/hpa:latest --requests=cpu=200m --expose --port=80创建 HPA 控制器
$ kubectl autoscale deployment php-apache --cpu-percent=50 --min=2 --max=10增加负载,查看负载节点数目
# 这是个压测实验,打开终端写个死循环,因为本身的hpa.tar就是谷歌开发的一款测试镜像,只要执行,那么占用的CPU会翻倍增加
# 目的是在Kubernetes集群中运行一个BusyBox容器,并让它不断地尝试从php-apache服务获取内容,以此暴涨php-apache容器内部的CPU使用率
$ kubectl run -i --tty work --image=busybox /bin/sh
while true; do wget -q -O- http://php-apache.default.svc.cluster.local; done过程是:先从expoter发送到Prometheus,Prometheus在通过MetricServer发送到集群内部,所以数据刷新会慢
当使用增加时,他会自动扩容,很快,但是收缩很慢,怕突然再来高并发
资源限制 - Pod
Kubernetes 对资源的限制实际上是通过 CGROUP 来控制的,CGROUP 是容器的一组用来控制内核如果运行进程的相关属性集合。针对内存、CPU、和各种设备都有对应的 CGROUP
默认情况下,Pod 运行没有 CPU 和内存的限额。这意味着系统中任何 Pod 将能够执行该节点所有的运算资源,消耗足够多的 CPU 和内存。一般会针对某些应用的 Pod 资源进行资源限制,这个资源限制是通过 resources 的 requests 和 limits 来实现
spec:
containers:
- image: wangyanglinux/myapp:v1
name: auth
resources:
limits:
cpu: "4"
memory: 2Gi
requests:
cpu: 250m
memory: 250Mirequests 要分配的资源,limits 为最高请求的资源,可以理解为初始值和最大值
一般我们会把request设置为设计需求量,比如我们可以用压测工具,apache的ab等,压测并发为10000时,记录当前使用的CPU和内存当做request;然后把这个值除以0.8,得到的值设置为limit,给他20%的冗余
当然,当request=limit的时候,会触发彩蛋,最高优先响应
比如说现在有两个服务,每个服务都需要2g内存,但是一共只有3G,每个给1.5也不够,那么就会优先给request=limit的,那么我们就可以在核心业务中设置request=limit,而且是把request变大等于limit
资源限制 - 名称空间
一、计算资源配额
apiVersion: v1
kind: ResourceQuota
metadata:
name: compute-resources
namespace: spark-cluster
spec:
hard:
requests.cpu: "20"
requests.memory: 100Gi
limits.cpu: "40"
limits.memory: 200Gi二、配置对象数量配额限制
apiVersion: v1
kind: ResourceQuota
metadata:
name: object-counts
namespace: spark-cluster
spec:
hard:
pods: "20"
configmaps: "10"
persistentvolumeclaims: "4"
replicationcontrollers: "20"
secrets: "10"
services: "10"
services.loadbalancers: "2"三、配置 CPU 和 内存 limitrange
apiVersion: v1
kind: LimitRange
metadata:
name: mem-limit-range
namespace: example
spec:
limits:
- default: # 默认限制值
memory: 512Mi
cpu: 2
defaultRequest: # 默认请求值
memory: 256Mi
cpu: 0.5
max: # 最大的资源限制
memory: 800Mi
cpu: 3
min: # 最小限制
memory: 100Mi
cpu: 0.3
maxLimitRequestRatio: # 超售值
memory: 2
cpu: 2
type: Container # Container / Pod / PersistentVolumeClaim超售值(limit)
- 超售发生在Pod的资源限制设置得高于其资源请求时,这意味着Pod在运行时可以使用超过其请求的资源,但不应超过其限制。
- 就像航空公司飞机有90个标准仓,10个商务舱,他会发售100张标准仓的票,因为可能有人不来了,如果都来了,那么就给他免费升舱到商务舱
- 如果这个集群有30个G的内存,给他10G的超售值,那么这个集群就有40个G的内存,有10G是假的,为了提高资源利用率
*IaaS就是这么赚钱的,云平台目前就是这种情况,正常来说十个CPU核心只能提供十个虚拟机服务,但是云供应商可能提供出20个虚拟机服务
因为基本不可能每个人的虚拟机都在724小时工作,利用率更高,但是不太稳定,就像真的需要40个G了,但是只有30个G,内核就会一直报OOME了**

