CoreOS和docker原本是兄弟公司,后来docker火爆了,CoreOS就搞了一些生态,就是docker运行需要的生态,CoreOS在Kubernetes中有很多应用
CoreOS开发的生态所有的都是容器化,操作系统,systemd都是容器,目前被红帽收购,未来可期的底层服务会影响上层服务,当docker火爆起来,就兴起了很多微服务,微服务只要在各自独立的小团体中进行优化就行,而且各自在自己的空间中,只需要解决自己的逻辑,不会冲突,提高了开发效率。
缺点是部署起来很难,而且需要最起码四台服务器,不适合小型公司。
而k8s只需要几条命令就可以完成一个集群的部署

目前有两种安装方式:
-
源码安装 - 将 k8s 组件以系统进程的方式运行,安装过程极其复杂
参考链接:https://cloudmessage.top/archives/k8s-install-1220 -
kubeadm - k8s 组件会以容器运行起来,具有良好的自愈性.
1.发展历程
IaaS:基础即服务(Infrastructure as a Service)
- kvm,exsi,OpenStack等等
PaaS:平台即服务(platform as a service
- 也有竞争对手:
- docker swarm:目前已经被放弃,没人用了,但是他的命令十分简单,成也简单,败也简单。
用人成本低,技术不一样,而且相k8s来说,功能有些少,在生产环境中需要在进行很多的二次开发
随着深入使用需要开发的越来越多,成本更大,k8s由全世界的顶级工程师一起开发,更全 - Apache的Mesos:以前是推特的底层运行平台,但是在2019年,推特由mesos全面转变为k8s
导致现在基本没有人使用Apache Mesos(2019 年 美国西部时间 5月2日下午7点,Twitter 公司在旧金山总部举行了一次技术发布会兼Meetup。会上,Twitter 计算平台(Twitter Computing Platform)产品与技术负责人 DavidMcLaughlin 正式宣布,Twitter 的基础设施将从 Mesos 全面转向 Kubernetes)
- docker swarm:目前已经被放弃,没人用了,但是他的命令十分简单,成也简单,败也简单。
- 目前基本上Kubernetes一家独大,2020年就达到了市场40%以上,并且在试用的20%,10%以上有意向使用Kubernetes,大概占据80%左右
SaaS:软件及服务(Software as a Service)
1.1Kubernetes的由来
Borg 是谷歌内部的大规模集群管理系统,负责对谷歌内部很多核心服务的调度和管理。Borg 的目的是让用户能够不必操心资源管理的问题,让他们专注于自己的核心业务,并且做到跨多个数据中心的资源利用率最大化
K8S站在了巨人的肩膀上,在十几年前谷歌就在用容器了,那时候国内还在按键手机呢,所以说差距还是有的
谷歌在十几年前就用了容器技术,直到docker搅局开源,既然第一个果子被docker摘了,那谷歌决定拿出brog系统,Borg系统已经运行了十多年的容器化技术,在这个基础上,谷歌的工程师用golang语言开发出了Kubernetes,同时也有自己的小心眼,比如网络方面,不同物理机之间想要通讯,那么需要扁平化网络,这个功能在Kubernetes中是没有的,但是在谷歌云上是直接就带的,但是在现在很多公司都推出了解决方案,比如COREOS,微软,国内的青云。
而且整个行业都在用Kubernetes,那么作为开发者的谷歌收益也是巨大的,他可以引领这个行业,国外选择云平台百分之九十都是选谷歌。
1.2 Borg系统:
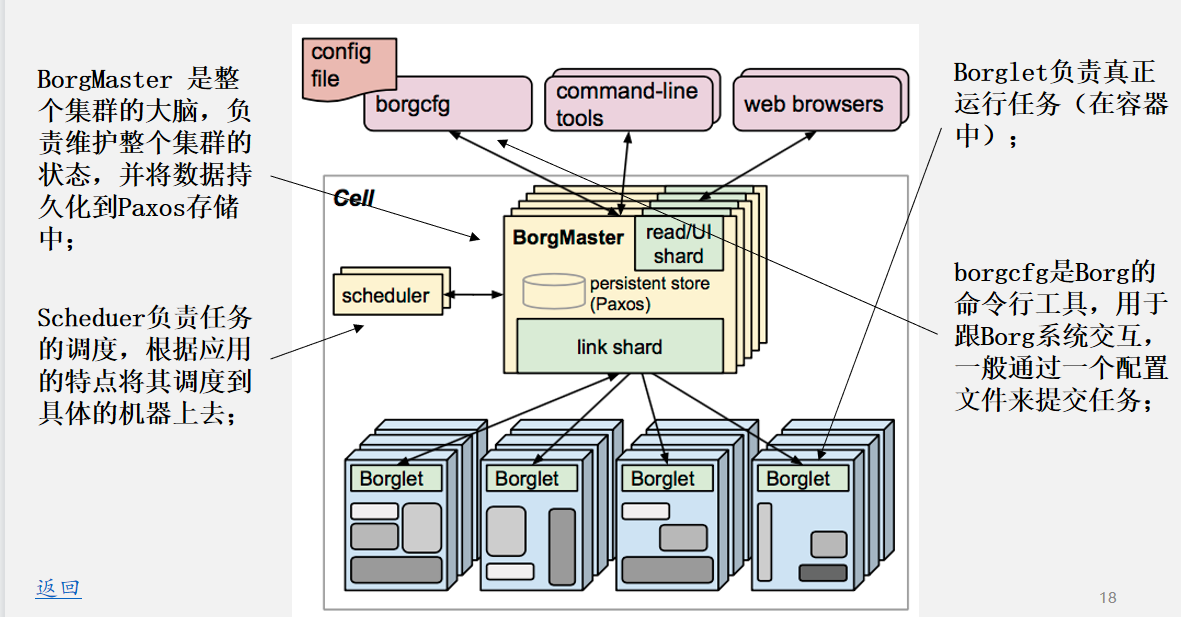
M/S架构: master work
BorgMaster: 是整个集群的大脑,负责维护整个集群的状态,并将数据持久化到Paxos存储中;
这个架构是一个无状态服务,本质上就是一个服务器,底层所有的组建都是通过http协议传输,沟通的
Paxos: 是谷歌开发而一个键值数据库,key=value,存储的所有数据都是kv结构,可以存储当前系统的所有元数据信息和相关配置参数
Scheduer 负责任务的调度,根据应用的特点将其调度到具体的机器上去;
当master发出指令后,scheduer获取以后,会自动和工作节点同步当前的资源可用量,从中选取最优节点去部署新的容器。
Borglet 负责真正运行任务(在容器中);工作节点
borgcfg 是Borg的命令行工具,用于跟Borg系统交互,一般通过一个配置文件来提交任务;1.3 k8s的优势
1.轻量级
- 在相同情况下,Kubernetes是golang写的,mesos是Java和c写的,Kubernetes的复用性非常高,在代码少的情况下能实现更多的功能
2.开源
- 开源,全世界共同开发,进步很快,而且很稳定,功能更多,发展更长远
比如我们公司开发了某一个功能开发了五个版本,那么很可能把一二版本开源,Kubernetes的功能就更全了
3.弹性伸缩
- 参考美团云,白天用的多,晚上基本一两个服务器就共用了,在互联网中,流量就是钱,大部分的收益就是广告。剩下的时间可以把空闲的资源卖出去。这个前提是集群可以收缩,在访问量少的时候,把资源吐出来,k8s就可以做到这点,在需要的时候再拿回来,而且快速,一两个小时就可以。传统虚拟化在一小时内把集群扩容到一百台,或者缩小回五台基本不可能
4.负载均衡
- 原理还是基于IPVS的
2.k8s组件说明
master端主要负责监控,管理,调度。node节点负责干活。
只要master活着,把master做高可用就可以。node死了清除换一个就好了
master采用RAFT共识算法,类似于Redis的投票,存活的节点要超过总数的半数.最起码有三个(能死一个),或者五个(允许死两个),七个(允许死三个).....
RAFT算法:最终一致算法
-
共识算法或叫感染算法,村口大妈一唠嗑,全村都知道了。一个组件接收数据,会分散式的传播给其他组件,但是可能有一点资源浪费,因为可能这个组件已经知道了(有数据了),但是还会再次接受
-
一个领导者,一堆小弟(跟随者),当大哥挂了,小弟变成竞选者,选出新大哥,其余的跟随。可以得知每个服务器的数据都拥有完整数据,而不是平均分给每个小弟。只有一个大哥leader。
-
如果在感染途中大哥挂了,每个小弟被感染程度不一样,就是数据不一致,那么就会选出数据最新的当大哥,但是最终都会感染完成,所以是最终一致算法。(如果多个节点同时变为候选者并发起选举,由于每个节点的超时时间是随机的,最先超时的节点将更有可能成为领导者。)
RAFT算法投票选举概述
- RAFT算法中的投票选举是确保集群中有一个领导者(Leader)的过程。在RAFT中,每个节点可以处于三种状态:领导者、跟随者(Follower)和候选者(Candidate)。领导者负责处理客户端请求并同步日志到其他节点,跟随者则等待领导者的指令,而候选者在特定条件下发起选举,争取成为新的领导者。
选举过程
-
选举触发:当一个跟随者节点在选举超时时间内没有收到领导者的心跳信号时,它会转变为候选者,并开始新一轮的选举。候选者会增加自己的任期编号(term),并向集群中的其他节点发送请求投票(RequestVote)的RPC消息。
-
投票规则:在一次选举中,每个节点最多只能投给一个任期编号的候选者一票。如果候选者的任期编号高于当前节点的任期编号,或者在任期编号相同的情况下,候选者的日志至少与当前节点的日志一样新,则当前节点会投票给该候选者。
-
领导者选举:如果候选者在选举超时时间内收到了超过半数的投票,它将成为领导者。领导者随后会周期性地向跟随者发送心跳信号,以维持其领导地位,并开始日志复制过程。
-
分裂投票避免:为了减少多个候选者同时获得足够票数的情况,RAFT算法使用了随机选举超时机制,确保候选者在不同的时间点发起选举,从而减少竞争。
在RAFT算法中,当一个由3个节点组成的集群中有一个节点宕机后,剩余的两个节点不会出现平局。这是因为RAFT算法要求在任何给定的任期内,领导者的选举必须获得超过半数节点的投票。在3节点的集群中,任何一个节点成为领导者都需要至少两个投票,因此当有一个节点宕机后,剩下的两个节点中的一个会成为领导者,而另一个会继续作为追随者。由于领导者选举的胜利条件是超过半数的投票,所以不会出现两个节点同时声称自己是领导者的情况.
组件图:
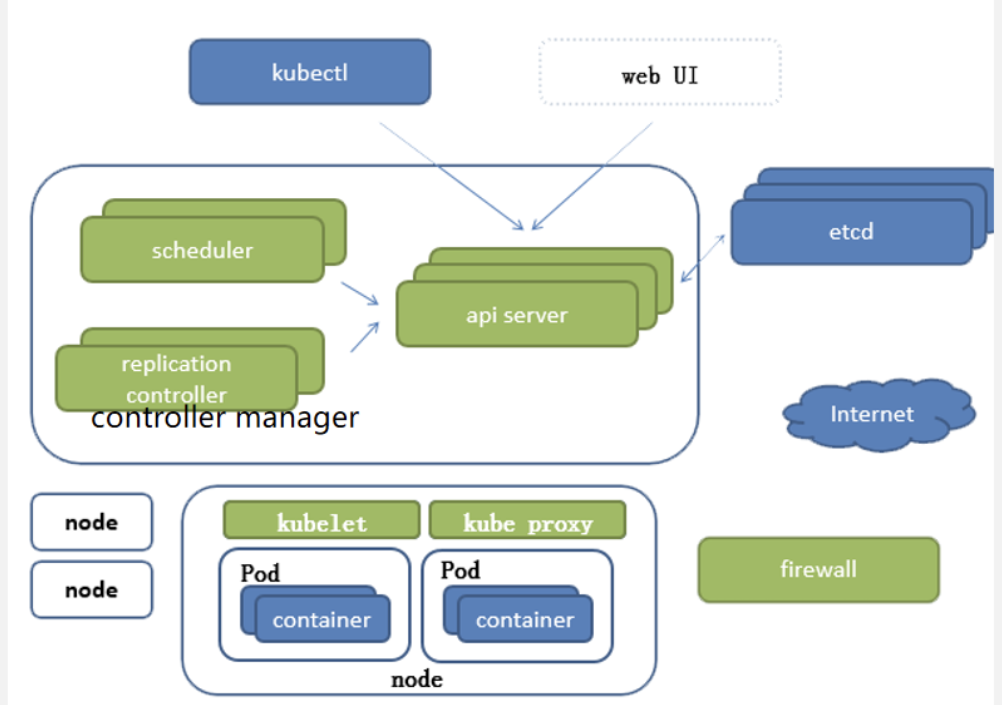
组件:身体就是组件
插件:外附骨骼,插进去实现本身没有的功能
附件:衣服
apiserver
-
所有组件的中枢,没有她的话所有组件就断了,他本质上是一个web服务器,通过自己的API(应用程序编程接口)处理任务。你给我发对应的报文,我给你返回对应的数据。不具备数据存储能力。
-
作为 Kubernetes 系统的入口,其封装了核心对象的增删改查操作,以 RESTful API 接口方式提供给外部客户和内部组件调用。维护的 REST 对象持久化到 Etcd 中存储
-
RESTful是一种风格,本质是通过http协议做C/S开发,就是习惯怎么定义上传动作,下载动作,删除动作,会有一个风格,就像是定义变量也有风格。比如张三=passwd,可以有小驼峰,大驼峰。驼峰式表达

这里get是获取,post是新增,但是可以在代码逻辑开发的时候可以让get是新增,让post是获取,但是大部分人都认为get是获取,这就是一种风格。

etcd
- 高可用的键值对数据库。专门存储整个集群的配置文件,配置参数的文件,是CoreOS开发的。
他是在每个节点上都有完整的数据,是存配置文件的,不是存元数据的,只要有他在,Kubernetes挂多少遍都可以再次起来。
etcd存储接口版本
- V2版是放在内存中,V3是放在磁盘中
放在内存中虽然快,但是如果断电,就直接没了。
v3放在磁盘中,经常读的放在内存中
现在看到的k8s都是1.14以后的,因为在这个版本把负载调度器从iptables变成了IPVS,效率提升很多
V3架构:
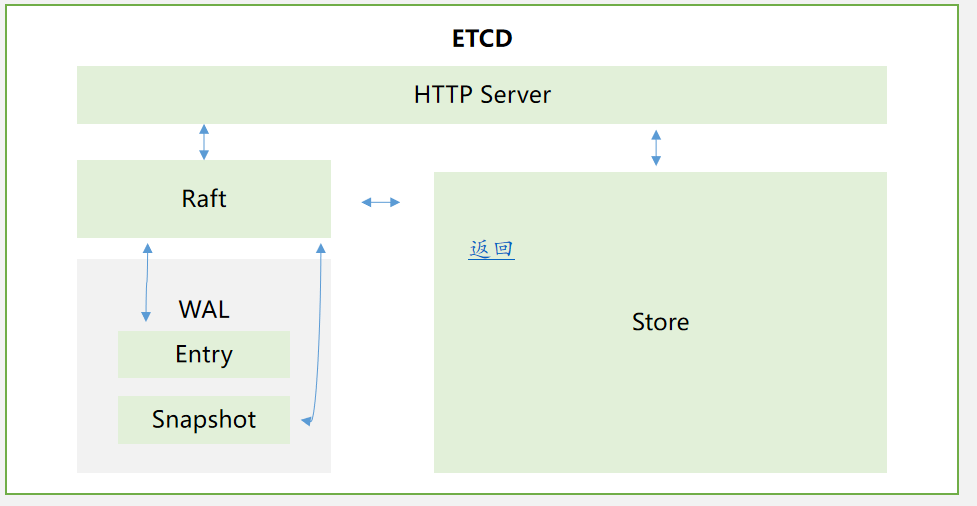
- WAl:预写入日志——在修改之前把需要修改的操作记录成日志,然后再写元数据
- Entry:入口
- Snapshot:快照功能
- Store:仓库
修改之前写入日志,并且有回滚功能,快照功能,然后放入仓库(存储桶)
如果直接写,突然断电就坏了,那么先写日志,写完日志哪怕断电变成损坏文件也没事,可以按照日志恢复
scheduler
- **调度器,最核心最本质的东西,负责将任务分发到对应的节点,要合理分配,不能让忙的更忙,闲的更闲,还要快,不能半天找不到需要调度的节点
- k8s官方的调度器是default,说是可以自己替换,但是他很牛逼,目前没人能替换
- 新建立的 Pod 进行节点 (node) 选择(即分配机器),负责集群的资源调度。组件抽离**,可以方便替换成其他调度器
controller manager
同步控制器,也就是管家,比如十个容器,有一个挂了,他就会去修复
负责维护集群的状态,比如故障检测、自动扩展、滚动更新等!
kubectl
命令行管理工具,和api server是通过https传输的,可以安装在任意节点。
kubelet
上面监听api server信息,下面连接CRI(容器管理引擎,容器运行时,这里就是指docker,这些都是CRI
是k8s的kubelet去连接容器的接口,(K8s无法直接链接容器),容器接口标准,也叫容器运行接口,CNCF建立的,除了docker以外全支持CRI接口
k8s想要连接docker的话还需要有垫片(docker-shim),垫片在中间做标准转换,一边连接k8s的CRI接口,一边连接docker的OCRI接口
OCRI
docker的容器运行接口
在1.24版本以后,k8s宣布废弃垫片,因为k8s的名头打出来了,影响力上升了,于是docker为了不被淘汰,现在自己维护这个垫片
在1.24版本以后,k8s宣布废弃垫片,因为k8s的名头打出来了,影响力上升了,于是docker为了不被淘汰,现在自己维护这个垫片
kubeproxy
代理调度器,当我们有负载均衡要求的时候,他会调用一个接口,netlink接口,这是linux内核暴露出来的一个接口,这个接口是IPVSadm工作的底层方式,ivpsadm通过这个接口去调用IPVS钩子函数进行捕获目标地址,然后完成转换的。
kubeproxy调用这个接口就相当于可以直接创建防火墙规则,调用钩子函数进行负载均衡
container runtime
容器运行时:CRI的一种叫法
- 能够让这个服务产生的本身。golang需要运行时和依赖,但是C语言不需要,因为linux就是C语言开发的 ,在这里的容器运行时就是docker
负责镜像管理以及 Pod 和容器的真正运行(CRI)
目前k8s是没有办法直接运行容器的,是通过调度CRI实现的,就是docker引擎本身
CoreDNS
插件,这个很重要
- 负责为整个集群提供 DNS 服务,给我们当前的k8s提供一个dns扩展功能。因为容器内部的ip不是固定的,但是加上一个dns,就可以给容器赋予域名,就固定了
Ingress Controller
为 K8S 中的服务提供外网入口
在Kubernetes中默认是IPVS负载调度,是四层调度,nginx是无法直接嵌入Kubernetes中的,所以Kubernetes提供了 ingress 接口,那么nginx就可以接入集群了,还有HPA等等,只要能提供七层负载能力的,就是一种ingress的表现。ingress就是提供七层负载能力的接口
Prometheus
属于附件,没用到任何一个k8s的接口
普罗米修斯
新一代的集群监控服务器,为整个集群提供资源监控能力
Federation
提供跨可用区的集群,提供不同数据中心的 K8S 集群的管理能力
在北京有个机房,在南京有个机房,如果想要两个Kubernetes集群一起管理,就需要用这个了
EFK
每个集群中的日志一起收集,一起检索
扩展
IPVS和iptables的区别
从k8s的1.8版本开始,kube-proxy引入了IPVS模式,IPVS模式与iptables同样基于Net,filter,但是ipvs采用的hash表,iptables采用一条条的规则列表。iptables又是为了防火墙设计的,集群数量越多iptables规则就越多,而iptables规则是从上到下匹配,所以效率就越是低下。因此当service数量达到一定规模时,hash查表的速度优势就会显现出来,从而提高service的服务性能
每个节点的kube-proxy负责监听API server中service和endpoint的变化情况.将变化信息写入本地的userspace/iptables/ipvs来实现service负载均衡,使用NAT将vip流量转至endpoint中。由于userspace模式因为可靠性和性能(频繁切换内核/用户空间)早已经淘汰,所有的客户端请求svc,先经过iptables,然后再经过kube-proxy到pod,所以性能很差。
ipvs和iptables都是基于netfilter的,两者差别如下:
- ipvs 为大型集群提供了更好的可扩展性和性能
- ipvs 支持比 iptables 更复杂的负载均衡算法(最小负载、最少连接、加权等等)
- ipvs 支持服务器健康检查和连接重试等功能
原文链接:https://blog.csdn.net/qq_36807862/article/details/106068871
红帽有个容器管理引擎:
Podman:既可以创建Pod,又可以创建容器
k8s的tab补齐方法
[root@docker01 ~]# yuma install -y bash-completion
[root@docker01 ~# source <(kubectl completion bash)
[root@docker01 ~]# kubectl describe pod ##可以使用了
# 这是临时生效,如果需要永久生效,得写在/root/.bashrc文件中
[root@kube-master01 ~]# cat .bashrc
# .bashrc
source <(kubectl completion bash)Linux root下的.bash文件作用
- .bash_profile: 这个文件主要用于交互式登录shell。它在用户登录时执行一次,用于设置环境变量和执行用户的.bashrc文件。
- .bashrc: 这个文件用于配置函数或别名,并且在每次打开新的shell时被读取。它包含了用户的个性化bash信息,如命令别名和环境变量的设置。
- .bash_logout: 当用户退出系统(退出bash shell)时,执行该文件中的命令。
- .bash_history: 这个文件保存了用户输入过的历史命令,便于用户查看和重复使用。
Linux中的/etc/profile和~/.bashrc有什么不同?
在Linux系统中,/etc/profile和~/.bashrc是两个不同类型的配置文件,它们在环境变量设置和启动脚本方面扮演不同的角色。
- /etc/profile是系统级别的配置文件,用于设置全局的环境变量和执行系统范围的初始化命令。当用户登录到系统时,/etc/profile文件会被执行,为所有用户提供统一的环境设置。
- home/.bashrc是用户级别的配置文件,用于设置当前用户的特定环境变量和执行用户级别的初始化命令。当用户登录并打开一个新的shell时,~/.bashrc文件会被执行,允许用户根据个人喜好定制环境。
.bashrc和.bash_profile的区别
.bashrc和.bash_profile都是Bash shell的配置文件,但它们在使用场景和执行时机上有所不同。
-
.bashrc文件主要用于配置交互式非登录shell的环境,它在每次打开新的终端窗口时被读取。这个文件通常用于设置环境变量、别名、函数等,这些设置适用于当前用户的所有非登录shell会话。
-
.bash_profile文件则用于配置交互式登录shell的环境,它在用户登录时执行一次。这个文件通常用于设置环境变量、启动必要的应用程序,以及读取.bashrc文件以应用用户的个性化设置。.bash_profile文件只在登录时被读取一次,不适用于非登录shell会话。
3.POD
3.1 什么是Pod
nginx和php.fpm是需要绑在一起的,而如果有多个nginx和多个php.fpm需要待在一起,但是这有违反了容器的原则,单容器单进程,所以就可以把他们放在一个豆荚中,看起来不属于一个容器,但是是一个整体
比如--network container:xxxx 和 --volume-from
网络也相同了,共享存储也一致了
在Kubernetes内部启动一个pod的时候,他会先启动pause容器,就是暂停容器,他启动以后,才会启动组容器
nginx和php共享组容器,共享网络栈,共享目录
如果直接nginx——php.fpm,那么偶合性不行,nginx死了PHP也活不下来
而pause的稳定性远高于nginx,pause一直在休眠基本不会死。
那nginx死了不会影响PHP,PHP死了也不会影响nginx
在Kubernetes部署的时候,Pod是最小单位!没有部署容器这一说,当然,一个Pod可以只有一个组容器
但是在一个Pod中,组容器的端口不能冲突
只要不冲突,一个Pod中组容器理论上可以有无数个
Pod是一个逻辑概念,没有实际的服务。但是可以演示,同一个Pod中的主机是可以文件共享的
Pause
初始化动作
初始化网络栈
挂载可能存在的存储卷
MainC 跟 Pause 共享网络栈 共享可能需要的存储卷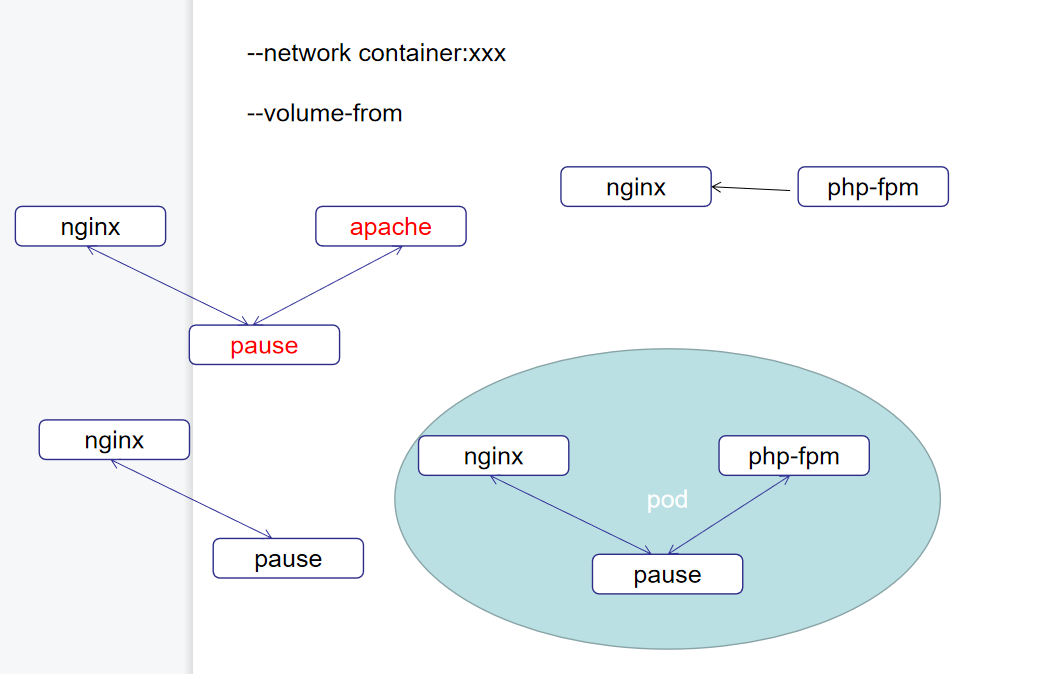
3.2 Pod创建有两种方式
自主式Pod:
像孤儿,没人纠正,如果Pod被杀死了就真没了
控制器管理Pod:
有监护人的,有啥错误可以被纠正,满足服务所有的期望哪怕被杀死了也可以在创建,只要控制器没死,3.3 Pod访问
pod 中不同容器间的访问
- 通过lo网卡
Pod 与 Pod 访问
同物理机
通过路由将数据报文发送至 pod 的外部 veth
跨物理机
利用 Linux 内核的隧道机制,实现 pod 间的访问(目前使用的 IPIP 模式,将 IP 报文封装在另一个 IP 包中,发送到对端)
