Service 的概念
Kubernetes Service 定义了这样一种抽象:一个 Pod 的逻辑分组,一种可以访问它们的策略 —— 通常称为微服务。 这一组 Pod 能够被 Service 访问到,通常是通过 Label Selector
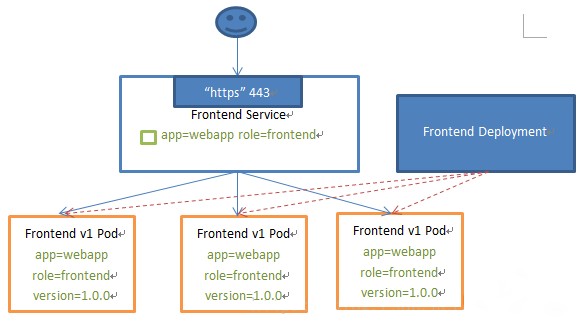
核心迭代
在 Kubernetes 集群中,每个 Node 运行一个 kube-proxy 进程。kube-proxy 负责为 Service 实现了一种 VIP(虚拟 IP)的形式,而不是 ExternalName 的形式。 在 Kubernetes v1.0 版本,代理完全在 userspace。在 Kubernetes v1.1 版本,新增了 iptables 代理,但并不是默认的运行模式。 从 Kubernetes v1.2 起,默认就是 iptables 代理。 在 Kubernetes v1.8.0-beta.0 中,添加了 ipvs 代理
在 Kubernetes 1.14 版本开始默认使用 ipvs 代理
在 Kubernetes v1.0 版本,Service 是 “4层”(TCP/UDP over IP)概念。 在 Kubernetes v1.1 版本,新增了 Ingress API(beta 版),用来表示 “7层”(HTTP)服务
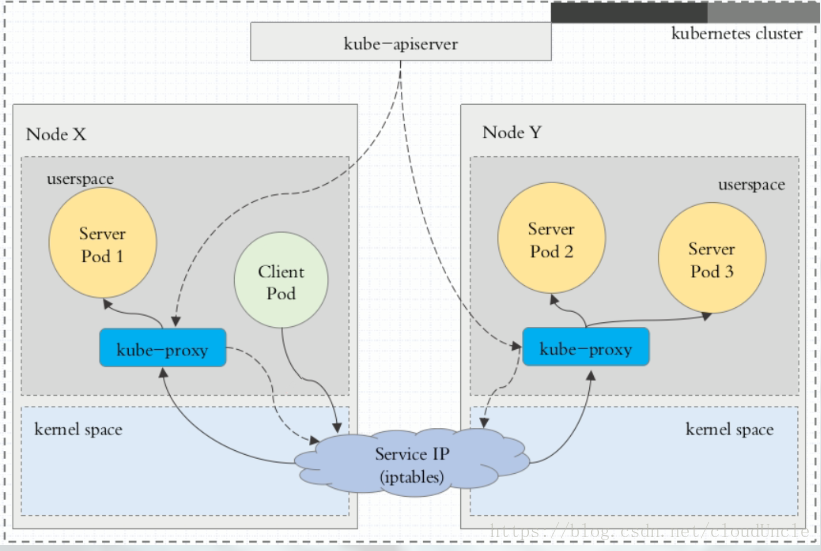
Ⅰ、userspace 代理模式
所有的流量需要被 kube-proxy 组件所代理,压力较大
[
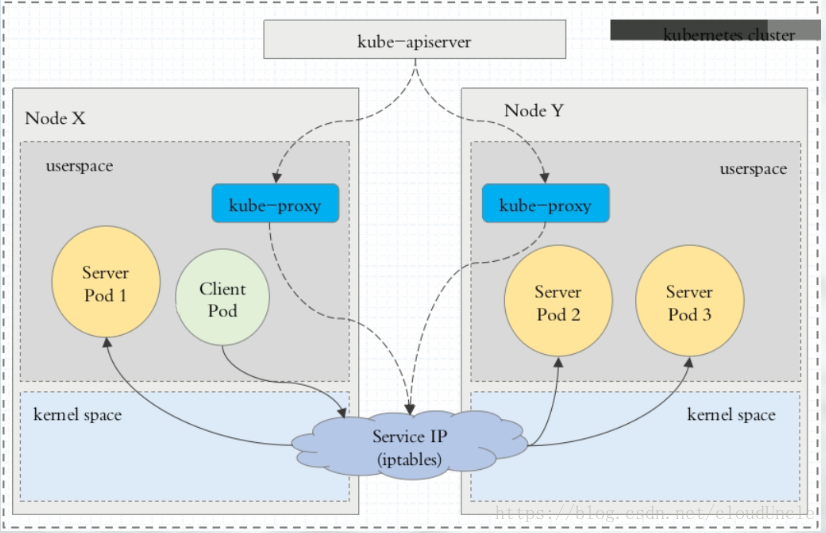
Ⅱ、iptables 代理模式
kube-proxy 只需要负责监听 apisever 集群信息通过 netlinks 实现 iptables 规则创建修改,所有的流量直接由本机的 iptables 转发完成
[
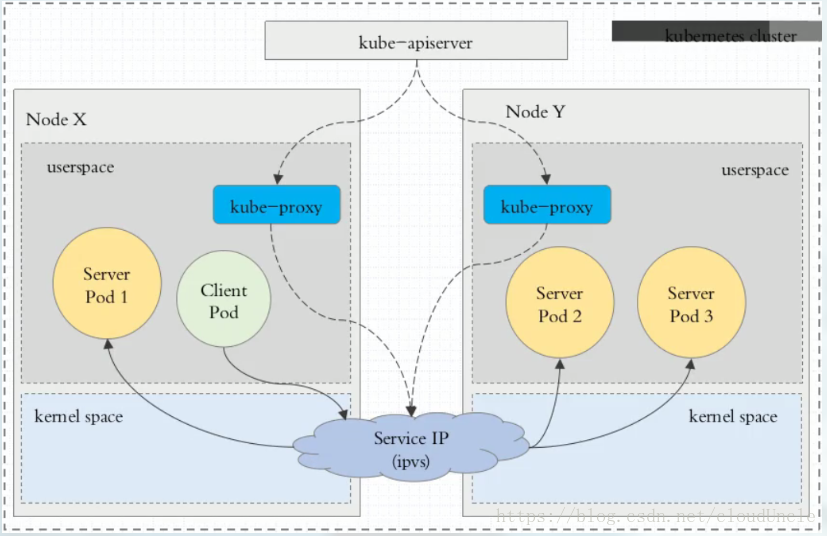
Ⅲ、ipvs 代理模式
kube-proxy 只需要负责监听 apisever 集群信息通过 netlinks 实现 ipvs 规则创建修改,所有的流量直接由本机的 ipvs 转发完成
注意: ipvs 模式假定在运行 kube-proxy 之前在节点上都已经安装了 IPVS 内核模块。当 kube-proxy 以 ipvs 代理模式启动时,kube-proxy 将验证节点上是否安装了 IPVS 模块,如果未安装,则 kube-proxy 将回退到 iptables 代理模式
[
限制
Service能够提供负载均衡的能力,但是在使用上有以下限制:
- 只提供 4 层负载均衡能力,而没有 7 层功能,但有时我们可能需要更多的匹配规则来转发请求,这点上 4 层负载均衡是不支持的
Service 的类型
- ClusterIp:默认类型,自动分配一个仅 Cluster 内部可以访问的虚拟 IP
- NodePort:在 ClusterIP 基础上为 Service 在每台机器上绑定一个端口,这样就可以通过 NodeIP: NodePort 来访问该服务
- LoadBalancer:在 NodePort 的基础上,借助 cloud provider 创建一个外部负载均衡器,并将请求转发到NodeIP: NodePort
- ExternalName:把集群外部的服务引入到集群内部来,在集群内部直接使用。没有任何类型代理被创建,这只有 kubernetes 1.7 或更高版本的 kube-dns 才支持
ClusterIP
[
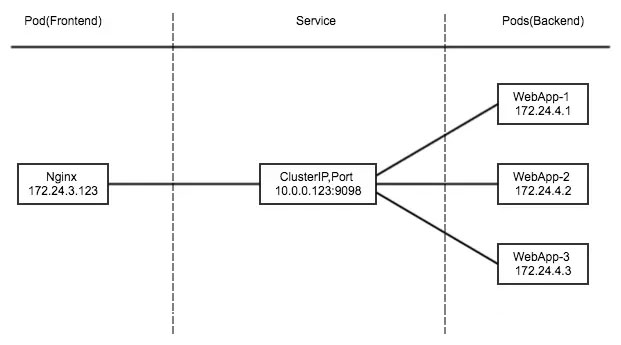
- 如果有一天Pod突然挂了,重新拉起的PodIP会变,nginx想要反向代理就需要去upstream中修改,太麻烦
- k8s的svc根据标签捕获,只要准备就绪并且标签符合,就会把他捕获到IPVS的规则列表里,实现负载均衡
- 而且会自动清理掉死掉的Pod的地址,并且把新的IP地址加入到IPVS里面,都会动态更新,所以只要nginx反向代理到svc的VIP就行了
- 这是在集群内部给其他组件使用的,不是给用户暴露使用的,只要Kubernetes集群不死,这个svc就不死,服务的VIP就不会变
为了实现图上的功能,主要需要以下几个组件的协同工作:
- apiserver:用户通过 kubectl 命令向 apiserver 发送创建 service 的命令,apiserver 接收到请求后将数据存储到 etcd 中
- kube-proxy:kubernetes 的每个节点中都有一个叫做 kube-porxy 的进程,这个进程负责感知service,pod 的变化,并将变化的信息写入本地的 ipvs 规则中
- iptables 使用NAT等技术将virtualIP的流量转至endpoint中
- ipvs:基于内核的钩子函数机制实现负载
创建 myapp-deploy.yaml 文件
[root@master manifests]# vim myapp-deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp-deploy
namespace: default
spec:
replicas: 3
selector:
matchLabels:
app: myapp
release: stabel
template:
metadata:
labels:
app: myapp
release: stabel
env: test
spec:
containers:
- name: myapp
image: wangyanglinux/myapp:v2
imagePullPolicy: IfNotPresent
ports:
- name: http
containerPort: 80创建 Service 信息
[root@master manifests]# vim myapp-service.yaml
apiVersion: v1
kind: Service
metadata:
name: myapp
namespace: default
spec:
type: ClusterIP
selector:
app: myapp
release: stabel
ports:
- name: http
port: 80
targetPort: 80Headless Service
有时不需要或不想要负载均衡,以及单独的 Service IP 。遇到这种情况,可以通过指定 Cluster IP ( spec.clusterIP ) 的值为 “ None ” 来创建 Headless Service 。这类 Service 并不会分配 Cluster IP, kube-proxy 不会处理它们,而且平台也不会为它们进行负载均衡和路由
# ipvsadm -Ln没有集群
# dig解析默认是所有pod的地址
# yum -y install bind-utils
[root@k8s-master mainfests]# vim myapp-svc-headless.yaml
apiVersion: v1
kind: Service
metadata:
name: myapp-headless
namespace: default
spec:
selector:
app: myapp
clusterIP: "None"
ports:
- port: 80
targetPort: 80
[root@k8s-master mainfests]# dig -t A myapp-headless.default.svc.cluster.local. @10.96.0.10-
Headless 服务是一种特殊的服务类型,它不会分配虚拟 IP,而是直接暴露所有 Pod 的 IP 和 DNS 记录。
-
通过标签来匹配pod,DNS查询反馈结果是给每个pod一个A记录
-
而且还可以在完全svc域名之前加上pod的name,单独指定某一个pod,例如:
{podname}.{headless-name}.{namespace}.svc.cluster.local nacos-1.nacos.pro.svc.cluster.local -
无头服务也就是没有VIP,也不会有集群
-
意义就在于他依旧可以dns解析。配合stateful使用,也就是可以给每个pod提供一个独立的域名,ip变了也可以访问
-
工作模式依旧是clusterip类型,但是cluster是none
$ nslookup statefulset-service.default.svc.cluster.local
Server: 10.96.0.10
Address: 10.96.0.10#53
Name: statefulset-service.default.svc.cluster.local
Address: 10.244.0.5
Name: statefulset-service.default.svc.cluster.local
Address: 10.244.0.6
Name: statefulset-service.default.svc.cluster.local
Address: 10.244.0.7优点
- 高度动态和可扩展:由于没有虚拟 VIP,Headless 服务对 Pod 的数量没有限制,具有高度动态和可扩展的特性。
- 直接访问 Pod IP 地址:与 ClusterIP 相比,在 Headless 服务中没有默认负载均衡器,因此可以直接访问 Pod 的实际 IP 地址。
- API 选择器的支持:在 Headless 服务中,支持 API 选择器。这使得我们可以根据标签选择特定的 Pod。
缺点
- 没有默认负载均衡器:由于没有默认负载均衡器,所以我们需要手动进行负载均衡。
NodePort
- nodePort 的原理在于在 node 上开了一个端口,将向该端口的流量导入到 kube-proxy,然后由 kube-proxy 进一步到给对应的 pod
- 新:将访问当前物理网卡端口的流量通过IPVS转发给后端的port
[root@master manifests]# vim myapp-service.yaml
apiVersion: v1
kind: Service
metadata:
name: myapp
namespace: default
spec:
type: NodePort
selector:
app: myapp
release: stabel
ports:
- name: http
port: 80
targetPort: 80nodeport类型的svc会将当前所有可用的网卡的随机端口(大于三万以上的)做成这个负载调度器的VIP,也就是ens33网卡的随机端口目前就是VIP,后端真实ip就是标签匹配的Pod地址。客户端只要访问这个30000+的端口,就能访问集群内部了
LoadBalancer
loadBalancer 和 nodePort 其实是同一种方式。区别在于 loadBalancer 比 nodePort 多了一步,就是可以调用 cloud provider 去创建 LB 来向节点导流
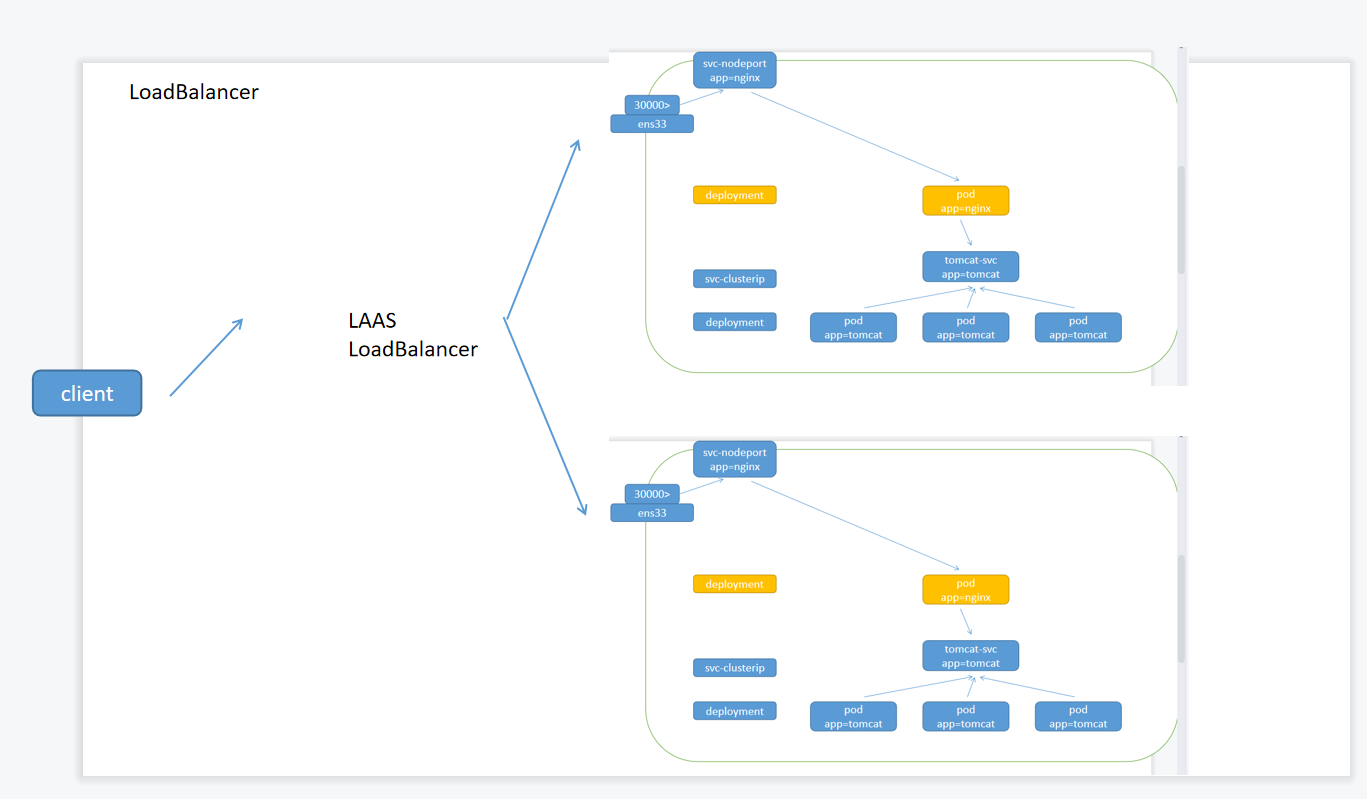
由于是nginx,客户一般只会访问默认的80端口,所以需要在外面在做一个四层负载
外面可以放两台硬件负载均衡机器,但是目前云供应商直接把ipvs模块给删了,逼着你去买IPVS服务。所以自己买完搭都搭不了
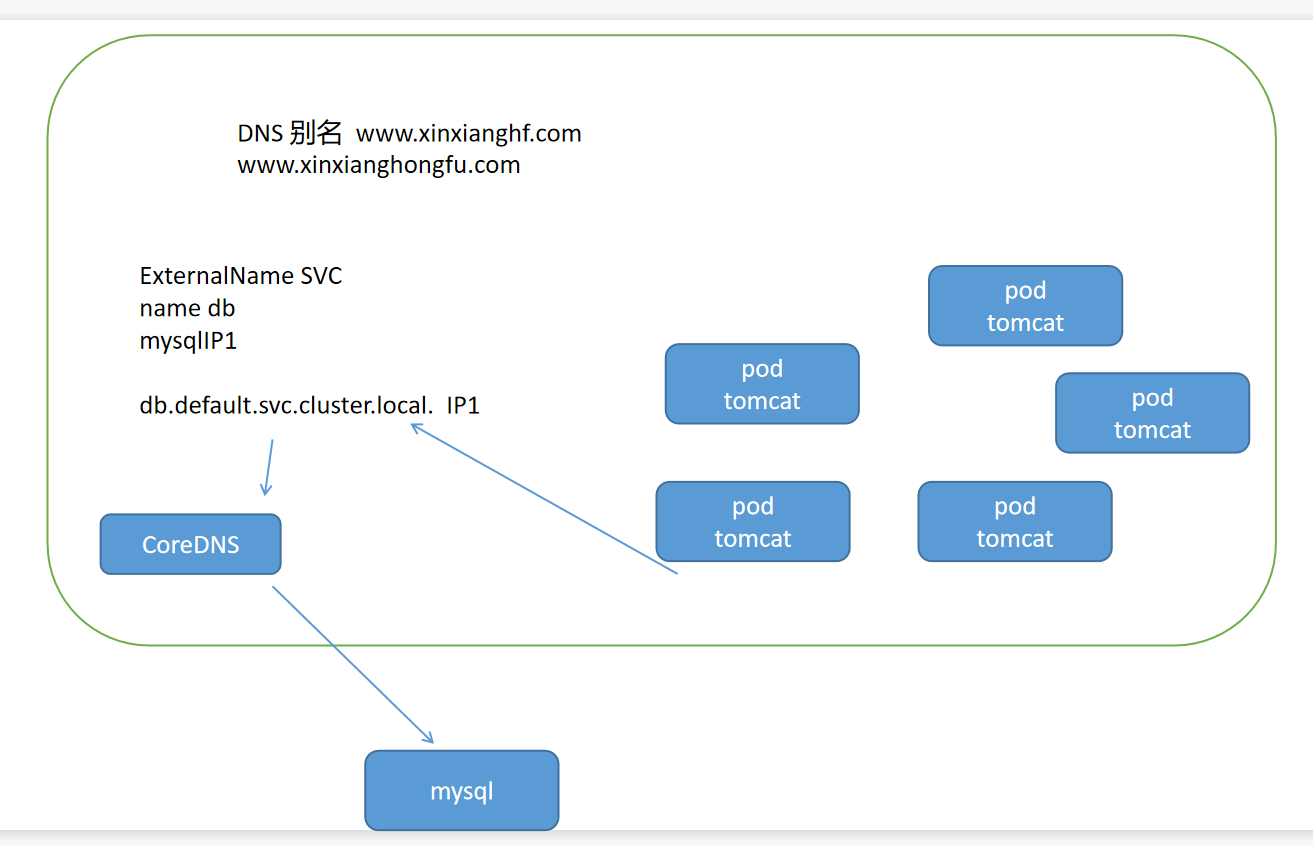
ExternalName
这种类型的 Service 通过返回 CNAME 和它的值,可以将服务映射到 externalName 字段的内容( 例如:hub.hongfu.com )。ExternalName Service 是 Service 的特例,它没有 selector,也没有定义任何的端口和 Endpoint。相反的,对于运行在集群外部的服务,它通过返回该外部服务的别名这种方式来提供服务
kind: Service
apiVersion: v1
metadata:
name: my-service-1
namespace: default
spec:
type: ExternalName
externalName: hub.hongfu.com当查询主机 my-service.defalut.svc.cluster.local ( SVC_NAME.NAMESPACE.svc.cluster.local )时,集群的 DNS 服务将返回一个值 my.database.example.com 的 CNAME 记录。访问这个服务的工作方式和其他的相同,唯一不同的是重定向发生在 DNS 层,而且不会进行代理或转发
ExternalName与Endpoint
简单来说,假如在k8s集群外部有一个mysql的服务器,如果是内网集群自己搭建的,我们有IP地址并且可以访问的情况下,可以写一个没有selector的clusterIP,之后再写一个同名的Endpoint,k8s会自动将他们关联到一起,这样就可以访问集群外部的mysql了
apiVersion: v1
kind: Service
metadata:
name: mongo
spec:
type: ClusterIP
ports:
- port: 27017 # Service端口
targetPort: 27017 # pod端口
————————————————
# 此服务没有 Pod 选择器。此操作将创建一个服务,但它不知道往哪里发送流量。这样一来,可以手动创建一个将从此服务接收流量的 Endpoints 对象。
kind: Endpoints
apiVersion: v1
metadata:
name: mongo
subsets:
- addresses:
- ip: 192.168.11.13
ports:
- port: 9200如果我们不是自己搭建的mysql集群,而是在云厂商买的mysql,而云厂商只提供了一个域名,那这个时候,就可以用externalname来将其进行转换
apiVersion: v1
kind: Service
metadata:
name: mysql
spec:
type: ExternalName
externalName: aliyun.mysql.com Ingress-nginx
资料信息
Ingress-Nginx github 地址:https://github.com/kubernetes/ingress-nginx
Ingress-Nginx 官方网站:https://kubernetes.github.io/ingress-nginx/
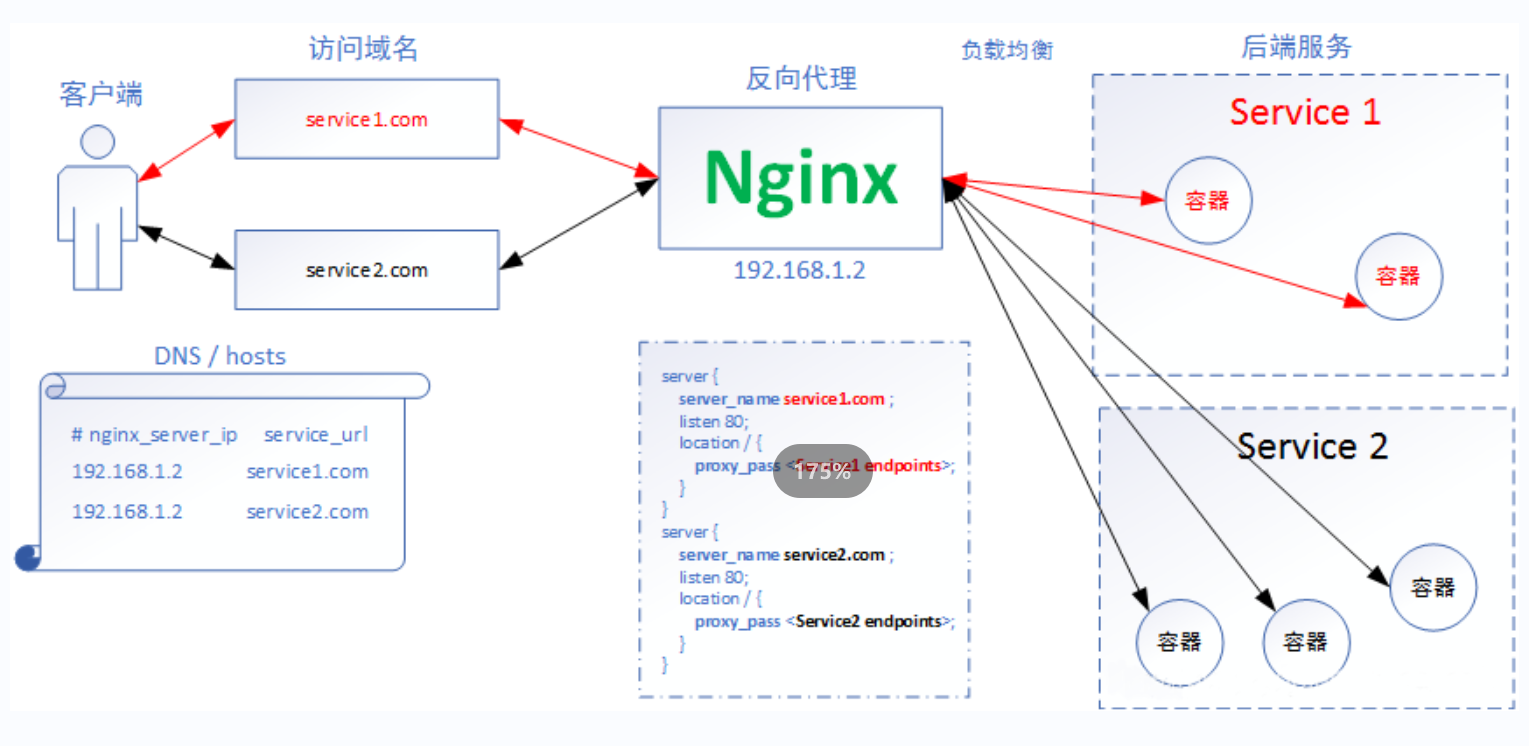
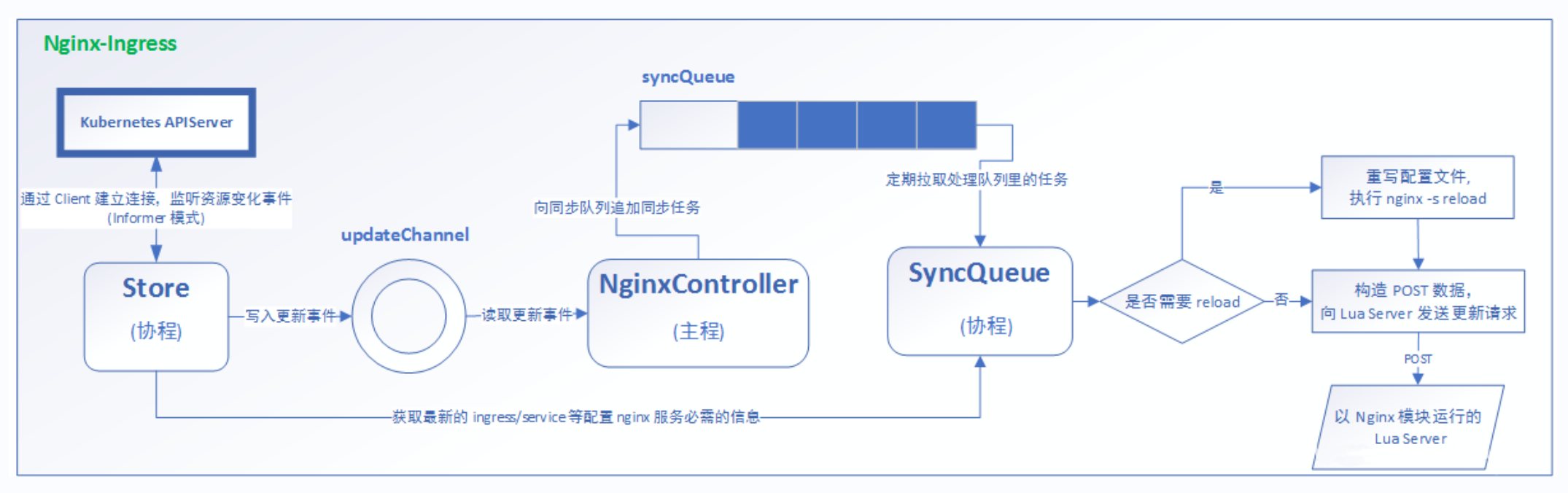
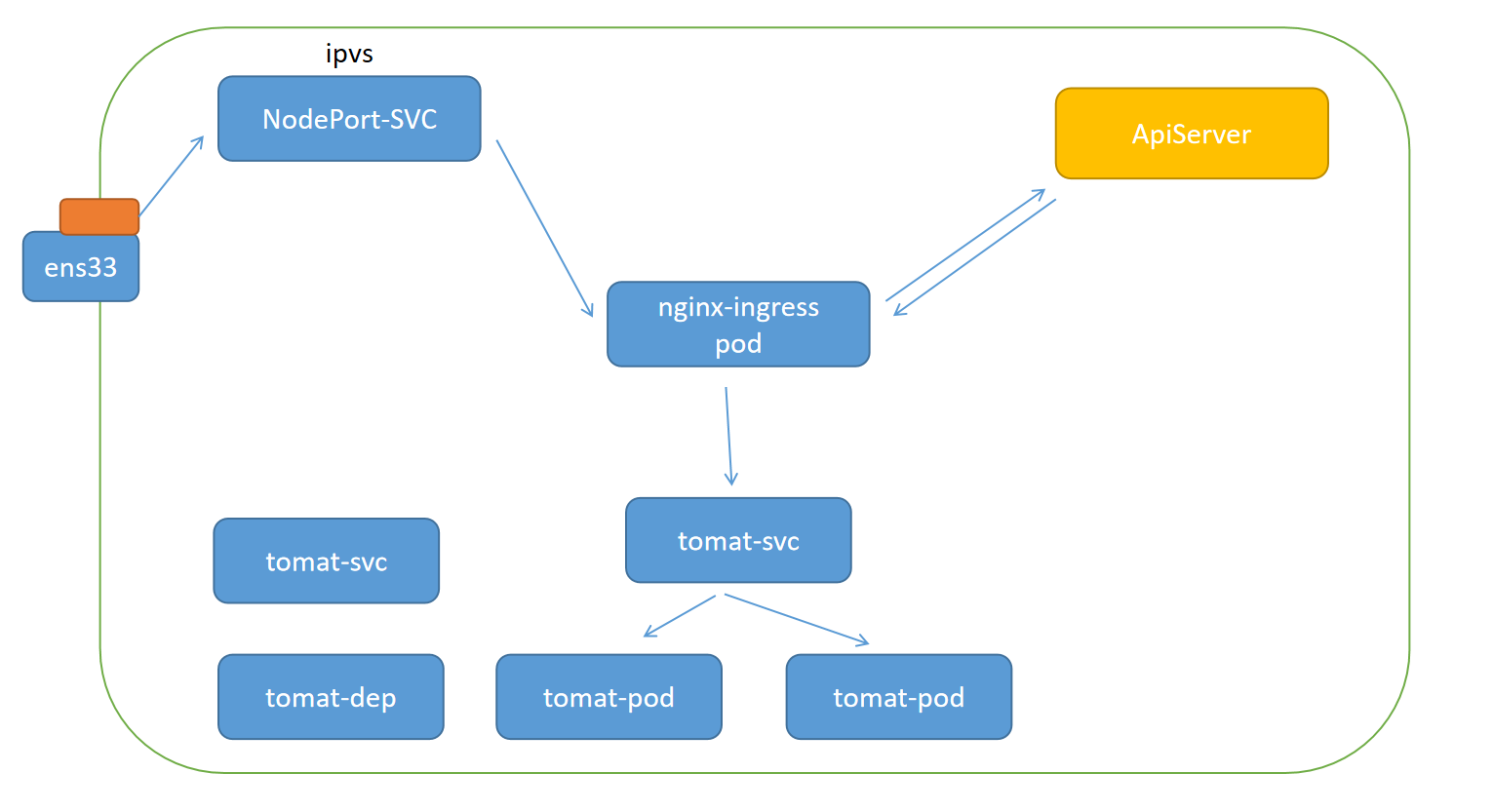
工作原理
ingress也是创建一个pod,他会去监听apiserver
部署 Ingress-Nginx
$ kubectl apply -f mandatory.yaml
$ kubectl apply -f service-nodeport.yaml这种系统级别的插件和附件,安装的文件需要保存下来(文件网上可以找到很多,对应自己需要的版本),需要删除的时候直接kubectl delete -f 文件名
就好了,不然根本删不干净,最好保存在/usr/local/kubernetes/下
常用的注释
annotations和label的区别:
-
label相当于国际公约,大家都能看懂SOS一样,是系统中Kubernetes的组件之间的约定方式
-
annotations:只有私有的开发者能用到,他不是组件,是第三方的开发者,如果想和用户做一些约定的话,就只能放在annotations里面,而不能放在label里面
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: ssl
namespace: default
annotations:
# 表示ingress的类型是nginx
kubernetes.io/ingress.class: "nginx"
# 强制开启https
nginx.ingress.kubernetes.io/ssl-redirect: "true"
# 修改限制文件大小
nginx.ingress.kubernetes.io/proxy-body-size: "5M"
# Nginx 在尝试连接到后端服务之前等待的超时时间。
nginx.ingress.kubernetes.io/proxy-connect-timeout: '600'
# Nginx 在发送请求到后端服务之前等待响应的超时时间。
nginx.ingress.kubernetes.io/proxy-read-timeout: '600'
# Nginx 在开始读取响应之前等待响应头的超时时间,以及在读取整个响应过程中等待更多数据的超时时间
nginx.ingress.kubernetes.io/proxy-send-timeout: '600'
Ingress HTTP 代理访问
deployment、Service、Ingress Yaml 文件
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: www1
spec:
replicas: 2
template:
metadata:
labels:
hostname: www1
spec:
containers:
- name: nginx
image: wangyanglinux/myapp:v1
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: www1
spec:
ports:
- port: 80
targetPort: 80
protocol: TCP
selector:
hostname: www1
---
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: www1
spec:
rules:
- host: www1.cedarz.com
http:
paths:
- path: /
backend:
serviceName: www1
servicePort: 80Ingress HTTPS 代理访问 HTTPS 会话卸载层
创建证书,以及 cert 存储方式
内网中就不需要443了,没有意义,只要外网访问nginx走443就好
所以在nginx到后端服务器的时候就会降级为http,这就是会话卸载层,利用ingress就可以实现
openssl genrsa -des3 -out server.key 2048
openssl req -new -key server.key -out server.csr
cp server.key server.key.org
openssl rsa -in server.key.org -out server.key
openssl x509 -req -days 365 -in server.csr -signkey server.key -out server.crt
kubectl create secret tls tls-secret --key tls.key --cert tls.crtdeployment、Service、Ingress Yaml 文件
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: ssl
spec:
replicas: 2
template:
metadata:
labels:
hostname: ssl
spec:
containers:
- name: nginx
image: wangyanglinux/myapp:v3
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: ssl
spec:
ports:
- port: 80
targetPort: 80
protocol: TCP
selector:
hostname: sslapiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: ssl
namespace: default
annotations:
# 表示ingress的类型是nginx
kubernetes.io/ingress.class: "nginx"
# 强制开启https
nginx.ingress.kubernetes.io/ssl-redirect: "true"
# 同时,这里也可以配置限制文件传输大小,会话保持时间等等
spec:
tls:
- hosts:
- ssl.cedarz.com
secretName: tls-secret
rules:
- host: ssl.cedarz.com
#表示后端使用的是http协议
http:
paths:
- path: /
backend:
serviceName: ssl
servicePort: 80Nginx 进行 BasicAuth
基础认证,类似于目录保护,需要输入账号密码,比如ELK,分布式收集日志,他就没有用户管理系统
那么就可以对源码进行二次开发或者ingress嵌套
yum -y install httpd
htpasswd -c auth foo
kubectl create secret generic basic-auth --from-file=authapiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: ingress-with-auth
annotations:
# 类型,文件,欢迎信息
nginx.ingress.kubernetes.io/auth-type: basic
nginx.ingress.kubernetes.io/auth-secret: basic-auth
nginx.ingress.kubernetes.io/auth-realm: 'Authentication Required - foo'
spec:
rules:
- host: auth.cedarz.com
http:
paths:
- path: /
backend:
serviceName: www1
servicePort: 80Nginx 进行重写
地址跳转,比如协议跳转(http—https),域名跳转(新旧域名替换)
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: rew
annotations:
nginx.ingress.kubernetes.io/rewrite-target: https://mbd.baidu.com/newspage/data/landingsuper?context=%7B%22nid%22%3A%22news_9216624084815729818%22%7D&n_type=-1&p_from=-1
spec:
rules:
- host: rew.cedarz.com
http:扩展
为何不使用 round-robin DNS作为负载均衡器
应用程序没有很好的处理 DNS 缓存的问题
现在我们应用的各种应用程序,背后连接的都是域名而不是ip,因为ip是会动态改变的
应用会将DNS域名解析的ip保存在自己的缓冲空间里,提高了访问速度,同时解决了更换IP不能访问的问题
但是这样反而不能负载均衡了,所以不能用DNS去进行负载调度器
为什么DR模式比NAT负载均衡强得多
因为他的出口流量(回应client请求的时候)不需要在经过负载调度器,直接从路由器出去了
Kubernetes集群中使用的是NAT模式
每个集群都有自己的调度器
每个节点的IPVS只负责当前节点的客户端的转发访问,整个节点也没有多少客户端
而且客户端被分发到不同的节点,由不同的节点取实现对应的转发请求,他本来的压力也不大
DR模式的缺点
- 需要修改arp响应和通告级别
- 不支持端口映射,源端口和目标端口必须一致
- 也就是说一个集群只能有一个web服务器(除非挨个改配置文件),太费劲了
如果需要自己写端口映射的话,最好在30000以上
Tomcat的优缺点
优点
- 开源免费
- 由于sun公司的加入(Java之父),对Java的理解可以说number1
缺点
- 静态资源的代理能力很差劲
- 所以现在一般都要在前面加一个nginx来对静态资源请求回应,动态资源在代理给Tomcat
service的会话保持
sessionAffinity
Service支持通过设置 sesionAfnitv实现基于客户端P的会话保持机制,即首次将某个客户端来源IP发起的请求转发到后端的某个Pod上,之后从相同的客户端1P发起的请求都将被转发到相同的后端Pod上,配置参数为service.spec.sessionAffinity。
sessionAffinity的参数设置
apiVersion:v1
kind: Service
metadata:
name: webapp
spec:
sessionAffinity:clinetIP
ports:
- protocol:TCP
port:8080
targetPort:8080
selector:
app: webappsessionAffinity会话保持时间
通过设置会话保持的最长时间,在此期间之后重置的客户端来源IP的保持规则,设置参数为service.spec.sessionAffinitvconfig.clientIP.timeoutseconds
apiVersion:v1
kind: Service
metadata:
name: webapp
spec:
sessionAffinity:clinetIP
sessionAffinitycongfig:
clientIP:
timeoutSeconds:300
ports:
- protocol:TCP
port:8080
targetPort:8080
selector:
app: webapp
